
Large Language Models (LLMs) are transforming how enterprises are using data to build knowledge, and use it for business functions. But understanding how LLMs make decisions remains a challenge. Their data and algorithms make continuous verification challenging, often leading to hallucinations. And without visibility into how conclusions are derived, validation becomes even more complex.
For enterprises, this can introduce risk. Without a structured LLM evaluation framework, there’s no reliable way to verify whether model outputs are accurate, safe, or compliant.
TL;DR
LLM Evaluation combines metrics, layered testing, regression checks, and automation to keep models accurate, fair, and production-ready.
In this blog, you’ll learn:
- Why enterprises need to move from testing to evaluation for LLMs.
- How a structured LLM Testing Architecture ensures accuracy, safety, and compliance.
- The step-by-step flow from prompt validation to continuous evaluation.
Want to validate your GenAI models
Why Use Evaluation for LLMs, Not Just Traditional Testing
Traditional testing checks if software works as expected—it’s rule-based and follows fixed outcomes. That approach works for predictable systems, where the same input always produces the same result.
LLMs work differently. They’re probabilistic, meaning the same prompt can lead to multiple valid responses depending on context, data, or phrasing. Because of this, testing alone isn’t enough.
Evaluation looks beyond correctness. It measures how the model behaves—its consistency, accuracy, and responsibility.
LLMs are evaluated for:
- Quality of output: Fluency, factual accuracy, and relevance.
- Ethical compliance: Avoiding bias, harm, or toxic content.
- Context alignment: Matching user intent and business needs.
So, while testing asks “Did it give the right answer?”, evaluation asks “Is this answer accurate, safe, and useful?”
Traditional software testing is based on predefined rules where the expected outcome is clear, But with GenAI, the output isn’t fixed. The model generates content based on learned patterns, and we can’t always predict the result. That’s why it’s crucial to test not just for functionality, but also for how the model handles context, ethics, and potential biases.
— Viswanath Pula, AVP – Data &AI, ProArch
Read the complete conversation with Viswanath Pula here
What Is LLM Evaluation
LLM Evaluation is the process of measuring how a large language model performs across accuracy, reliability, and safety. It helps teams understand not only the quality of outputs but also how consistent and responsible they are. Through structured evaluation, organizations can identify weaknesses, track improvements, and ensure models meet enterprise and ethical standards before deployment.
Benefits of LLM Evaluation
- Increase Trust and Reliability – Validating AI outputs ensures that the model consistently delivers correct and responsible results. It’s the foundation of reliability helping users trust that every response is factually sound and contextually relevant.
- Reduce Hallucinations and Errors – Even the best models can generate convincing but false information. Rigorous and continuous testing helps detect and minimize these hallucinations, ensuring outputs stay anchored to real data and verified sources.
- Promote Fairness and Accountability – Bias can quietly shape AI behavior in ways that erode fairness. By evaluating responses through diverse datasets and human review, you can uncover and correct bias before it impacts users.
- Maintain Business and Regulatory Compliance – Evaluation verifies adherence to data privacy, ethical guidelines, and industry regulations, minimizing compliance risks.
- Enable Continuous Improvement – Post-deployment evaluation and feedback loops help refine performance and align models with evolving business goals.
You may also like
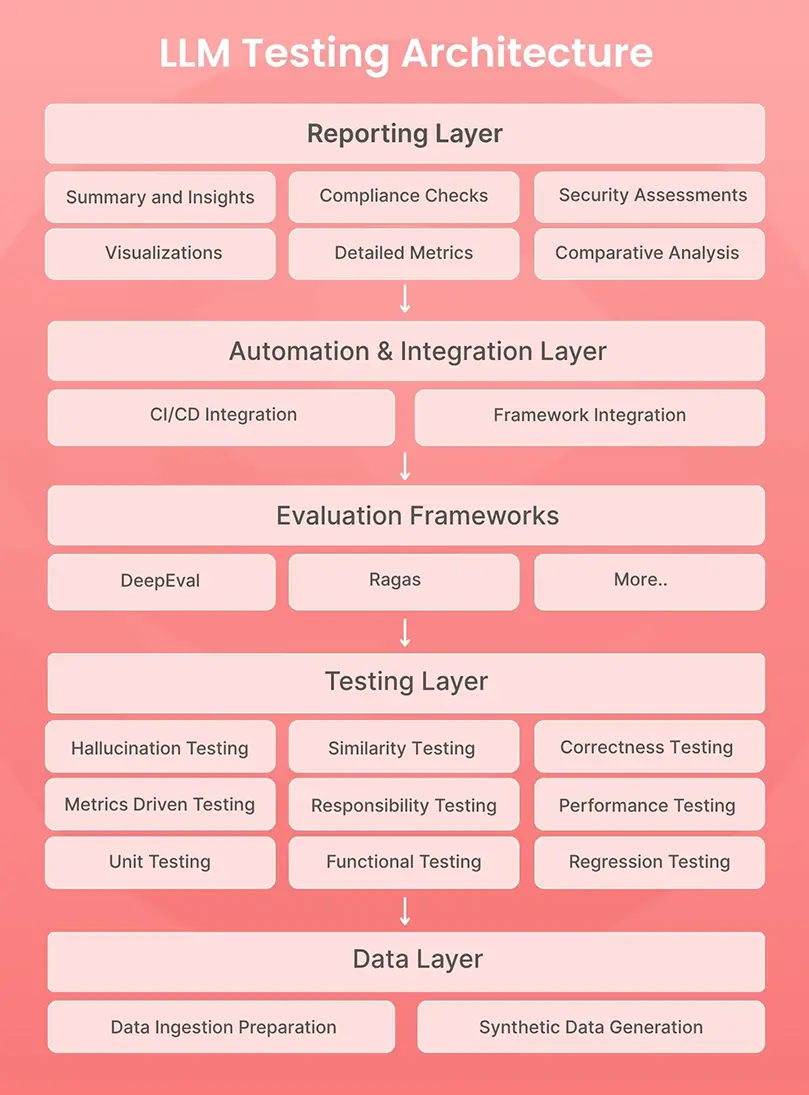
What is LLM Testing Architecture
LLM Testing Architecture is the structure that connects five key layers—Data, Testing, Evaluation, Automation, and Reporting—to make validation structured, measurable, and ongoing. Each layer plays a clear role in keeping models accurate, safe, and production-ready.
5 key layers of LLM Testing –
I. Data Layer
The foundation of testing starts with high-quality data. This layer handles everything from collecting and preparing data to creating test scenarios.
- Data Ingestion and Preparation: Gather, clean, and organize data from different sources, including LLM and RAG systems, to build a reliable test base.
- Synthetic Data Generation: Gathering and managing data, particularly in case of niche use cases, can be challenging. To overcome limitations in real-world data, organizations often turn to generating synthetic data.
II. Testing Layer
This layer checks how the model behaves and performs in different conditions.
- Unit Testing: Validate individual components or model functions.
- Functional Testing: Test complete workflows and real-world tasks.
- Regression Testing: Ensure updates don’t break existing functionality.
- Performance Testing: Measure response speed and scalability.
- Responsibility Testing: Identify and reduce bias or harmful responses.
- Metrics-Driven Testing: Use defined metrics like Faithfulness, Relevance, Context-aware, etc to track performance and quality.
- Correctness Testing: Verify that model outputs are meaningful and accurate.
- Similarity Testing: Compare outputs with human responses or reference data.
- Hallucination Testing: Detect and minimize false or fabricated content.
- User Acceptance Testing: Validate that model outputs meet user expectations, business needs, and real-world usability standards.
III. Evaluation Frameworks
This layer measures overall model quality and consistency using defined metrics and tools. Organizations like NIST and OpenAI have issued testing guidelines for LLMs, emphasizing ethics and performance. Among open-source options, DeepEval and RAGAS stand out. With 30+ open-source frameworks available, teams can choose tools that best fit their testing needs and ensure model quality aligns with industry standards.
- DeepEval and RAGAS: DeepEval helps measure response quality—coherence, relevance, and consistency—while RAGAS focuses on evaluating retrieval-augmented generation models for accuracy and context.
- Custom Metrics: Adapt evaluations to specific business or domain requirements.
IV. Automation and Integration Layer
Automation ensures testing and evaluation happen continuously, not just once. This layer helps detect issues early, maintain consistent standards, and shorten the release cycle.
- CI/CD Integration: Automatically trigger tests every time the model is retrained or updated.
- Framework Integration: Work smoothly with platforms like TensorFlow, PyTorch, or existing DevOps pipelines.
V. Reporting Layer
The final layer turns technical results into insights that teams can use for decisions.
- Reports and Dashboards: Present evaluation outcomes such as accuracy, bias, and compliance in an easy-to-read format.
- Visual Insights: Highlight performance trends, retraining effects, and areas needing improvement.
Human oversight remains critical in this reporting layer. Subject matter experts review the model’s outputs, confirming accuracy and relevance. This human element helps catch and report any “hallucinations” or unexpected outputs, ensuring final accountability and quality alignment with domain standards. This layer closes the loop—making it simple to monitor model quality, track progress, and share results across teams.
Meet Our AI Experts

Lakshman KavetiManaging Director, Data, AI &
App Dev, ProArch

Viswanath PulaAVP – Data & AI,
ProArch
How LLM Evaluation is Done
- Input Prompts: We begin by creating prompts that mirror real user interactions and expected scenarios. These prompts are then fed into the AI system to assess how well the model interprets and responds across varied inputs.
- Evaluate Responses: The model’s outputs are evaluated for accuracy, relevance, and appropriateness. Any hallucinations, incorrect information, or unsafe content are flagged. This step includes human validation to ensure deeper judgment where automation alone falls short.
- Monitor KPIs: Throughout the process, we track measurable indicators such as accuracy, relevance, latency, and safety. Continuous monitoring helps detect model drift or unexpected behavior as updates and retraining occur.
- Feedback: Insights from automated tools and human reviewers are consolidated to highlight both strengths and areas of improvement.
- Implement Improvements & Repeat: Based on the feedback, prompts are refined, and the model is fine-tuned or retrained. And regular human reviews create a continuous cycle of optimization, helping the model stay effective and aligned with business priorities.
Ready to Validate Your AI Systems with Confidence?
Building and deploying LLMs isn’t just about generating responses—it’s about ensuring every output is accurate, ethical, and aligned with context. Continuous evaluation helps detect hallucinations, reduce bias, and maintain compliance, while keeping performance optimized over time.
At Enhops, our AI-driven QA framework strengthens every layer of LLM testing — from prompt validation and hallucination detection to bias monitoring and compliance tracking.
We help enterprises:
- Reduce hallucination rates and maintain factual integrity
- Shorten release cycles through automated evaluation in CI/CD
- Build Responsible AI systems that are transparent, safe, and production-ready
Ready to validate your AI systems with confidence?
Reach out to Enhops to establish your continuous LLM testing and evaluation framework — and transform how your enterprise ensures AI quality.


